Blockchains are hitting scaling bottlenecks as more dApps and users onboard. The challenge lies in keeping blockchains decentralized, secure, and energy-efficient as we scale. In this article, we discuss vertical scaling techniques such as block size and block frequency tweaks. We also discuss horizontal scaling techniques such as using multiple chains, Layer 2s, sharding, history expiry, data availability sampling, and proposer-builder separation.
⛔ Prerequisites:
👉🏽 How should you use this article?
We wrote this article to synthesize the knowledge we gathered over the last few weeks and simplify it to a few fundamental concepts. We’ll keep our piece short and focus the discussion on scaling blockchains, with links to in-depth resources. Use this as a map if you’re new to the topic, or as a review after you’ve returned from the rabbit hole.
We intend to keep the sections updated as the field evolves, So check back from time to time (or subscribe!) if you want to keep up with how this space evolves.
The Basics
ℹ️ Before we dive in let’s take stock of what a blockchain is and why we want them in the first place. As we dig deeper, definitions will start getting confusing and lines will start getting blurry. It is important to agree on a few core principles and the big picture so we don’t get lost in the weeds.
Here is a quick high-level overview of how a Proof of Stake Blockchain works:3
- A blockchain is a shared4 database5, where no edits are allowed.6 You can only add new rows and a set of rows makes a block.
- To add your row to a new block, you send the data (called transaction, or TX) you want to add over a peer-to-peer network.
- An important property of public blockchains is Censorship Resistance. Any anonymous wallet should be able to add any valid transaction to the database without unfair delays. This makes blockchains permissionless.
- We have multiple computers (called validators) to help us add the transactions to the database in a secure way.
- In Proof of Stake, a random validator is picked every few blocks. This validator is called the Proposer for these blocks. The Proposer:
- groups one or more transactions together into a block
- does any computation required (in the case of smart contracts) and summarizes the result.
- proposes this bundle to the other validators to add to the end of the chain.
- Each validator checks if the computation is okay, and decides whether to accept the block.9.
- Once the block is decided, if anyone broke the rules, they are penalized. This is called “slashing” and is also encoded as a transaction that validators have to vote on.
- From 6, we see that the “truth” in a blockchain is determined by what most of the validators say is the truth.
- So, if most of the validators10 cheat the same way, consensus can still be achieved. And the minority who didn’t cheat will be “lying” even if they followed the earlier rules.
- To ensure that the validators don’t collude against the interest of the community11 (e.g. via censorship or by rewriting the rows in the database), anyone should be able to verify the state of the blockchains. This is what gives blockchains their trustless property.
- To maximize the key properties of resilience, permissionlessness, and trustlessness, public blockchains must be as decentralized as possible. To maximize decentralization, we have to make it easy for people to validate the state of the blockchain themselves.
💡 Proof of Work is a throttling12 mechanism Most of this article talks about Proof of Stake (PoS) blockchains. In PoS chains, the block proposers only have to do the work required to build the block. Most of the scaling strategies are about reducing this work or getting the validator to do more of it.
In a Proof of Work (PoW) blockchain, you need to build the block AND solve a puzzle, which is explicitly designed to be random and difficult. So PoS is inherently a more scalable system than Proof of Work, but it is a much more complex system with more moving parts 13.
Why is Scaling in the Spotlight?
What does it mean to scale a blockchain? In short, we want to add as much data as possible every second.14
Over the last few years, we’ve seen more and more use cases being built on top of public blockchains. If we look at Ethereum, the number of transactions per day has skyrocketed from ~10k/day in Jan 2016 to ~1M/day in Jun 2022 - a 10x increase.
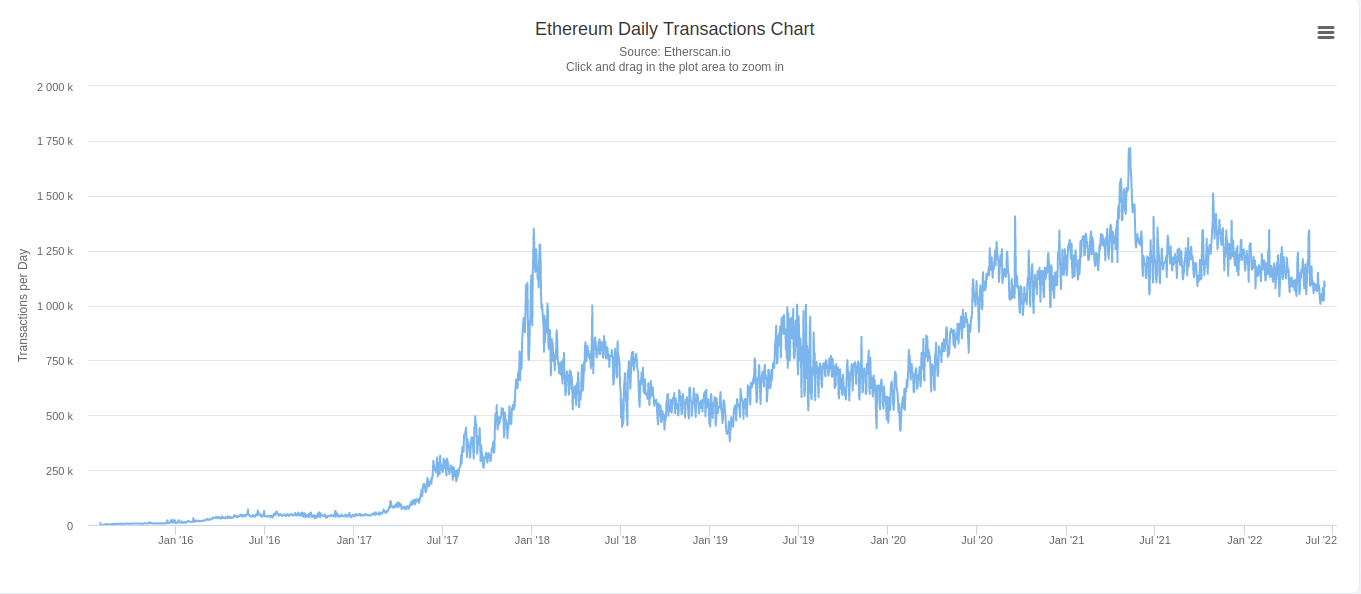
The number of active wallets per day on Ethereum in June 2022 is about 700k.15
Assuming more and more use cases are built on top of blockchains16, it is not difficult to imagine a world in the future where activity on blockchains will be on the order of 100x to 1000x what it is today.
However, we see the gas fees 17 in Ethereum already become prohibitively expensive for the average user when there’s a sudden spike in interest in a particular protocol. We’ve seen some low-fee blockchains become clogged or go down when they encounter such spikes too.
The problem will only get worse as more users and developers onboard the Web3 ecosystem.18

Scaling Computer Systems
In computer science, there are two main approaches to scaling:
-
Vertically: Make nodes19 more and more powerful. This is what Web1 servers typically looked like since most users would only be consumers of the data. As traffic increased, you’d upgrade servers’ specifications to keep up. Beyond a certain point, scaling vertically stops being a cost-effective way.
- As you scale blockchains vertically, they become more centralized since the minimum requirements for running a node increase. Thus, we see highly specialized computers20 dominate the share of validators.
- Horizontally: Add more nodes and split the work between them. Web2 systems generally evolved this way to distribute web traffic evenly between their centralized servers and databases. The amount of coordination overhead incurred by the system depends upon the number of nodes21 and how tightly controlled the environment is.22
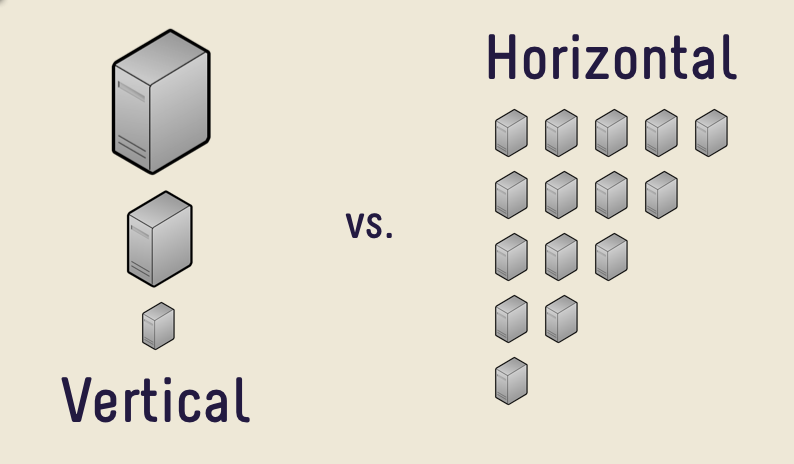
For decentralization in Web3, blockchains need to have low barrier to entry for anyone to participate in securing the blockchain. So we want to avoid imposing stringent requirements about their network speed or system specifications. This inevitably leads to trade-offs. For example, if you cant require that everyone needs to vote within a certain period of time, it becomes harder to guarantee that the blockchain will reach consensus within a certain period of time. The block times are hence slower, and it doesnt scale as much.
In summary, if you scale vertically (easier way), you compromise on decentralization. If you want to keep/improve decentralization, you have to contend with the challenges and bottlenecks of horizontal scaling. We can start to see a fundamental tension between scaling and decentralization. One way to look at this tension is the “Blockchain Trilemma”, a term coined by Vitalik Buterin. This underlies all conversations around scaling.
There are a few questions to ask while evaluating any blockchain scaling approach:
- Does this approach make blockchains more or less decentralized?
- Where are the attack vectors of each approach? How can we mitigate them?
- How much can we scale current systems with this approach?
With all that context out of the way, let’s try and scale blockchains!
Vertical Scaling - Bigger Nodes are Fine
💡 Most of the vertical scaling discussion are mainly aimed at PoW chains.
Let’s assume we have a network that produces a block every 10s, and every block can hold a maximum of 100 transactions.
This maximum limit is called a maximum block size. Why do we have such a limit? If everyone who wants to include a transaction in a block gets to include it, it might not be possible to process it in 10 seconds. So we need some kind of limit to ensure whoever is producing a block can do it in 10 seconds. The way people include their transaction over others is by getting into an auction for the blockspace, by paying a higher amount for a unit of gas.17
If we increased the maximum blocksize to 200 transactions, more transactions could be included in each block. However, if the block size is too large only those with powerful computers will be able to get the block ready within 10s.23
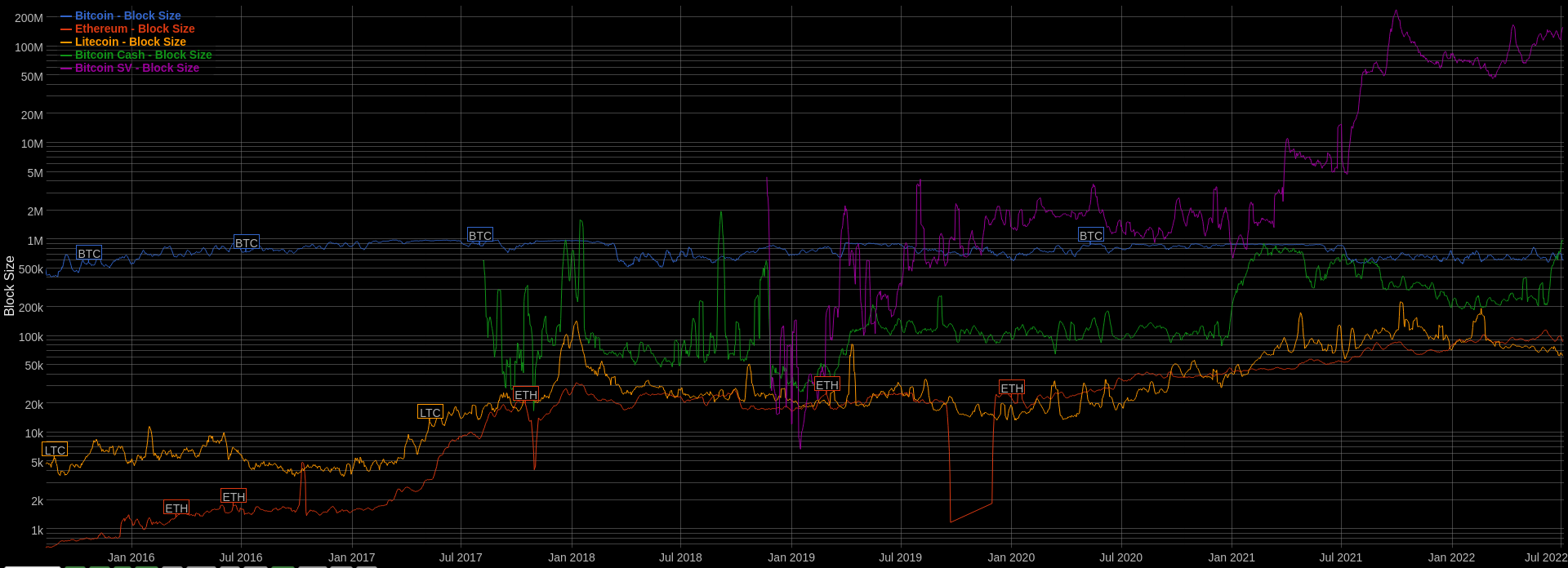
Another way to scale the TPS is to produce a block every 5s instead of every 10s.24 This also creates a centralizing force since it requires a highly specialized computer.2526 This prices out the low-tier nodes.27
Ultimately, this is a balancing act for protocols. A few Alt L1s are taking a vertical scaling approach, but Ethereum and Bitcoin are resisting such changes. On the other hand, Binance Smart Chain maintainers don’t care if the requirements are high, so they increase the blocksize as demand increases. Since they use Proof Of Authority,28 they only select validators with powerful setups capable of handling a block every 3 seconds, and they keep increasing the blocksize as the demand increases. Solana does something similar - anyone can run a validator on Solana, given they can meet the high bar for minimum specifications to keep up with ~400ms blocktime. They hypothesize that computers will get faster with time, so we can afford to have system requirements that are considered heavy today.29

Horizontal Scaling - Don’t Give Up On Decentralization!
So if we want the everyday person with a relatively modern consumer PC to be a validator, how do you scale? The core idea is to distribute the work required across many participants such that each participant does less work while keeping other participants in check.
💡 In 2022, some of these are cutting edge ideas and active areas of research. As such the implementations and search spaces are intertwined - you need the entire picture of scaling to understand how the different levers affect each other’s effectiveness and work together to ensure the security and liveness of the network. For example, increasing the storage requirements by making calldata cheaper might hurt decentralization, but that can be counterbalanced by introducing history expiry at the same time.
Rise of Layer 2s
A Layer 2 (L2) is a setup where some of the computation is pre-processed by a different set of nodes so the validators on the L1 don’t have to, and then post the result to the L1.30 This can take various forms depending on what is processed by L2 and what is finally added to the L1.
Hash Time Locked Contract (HTLC / State Channel)
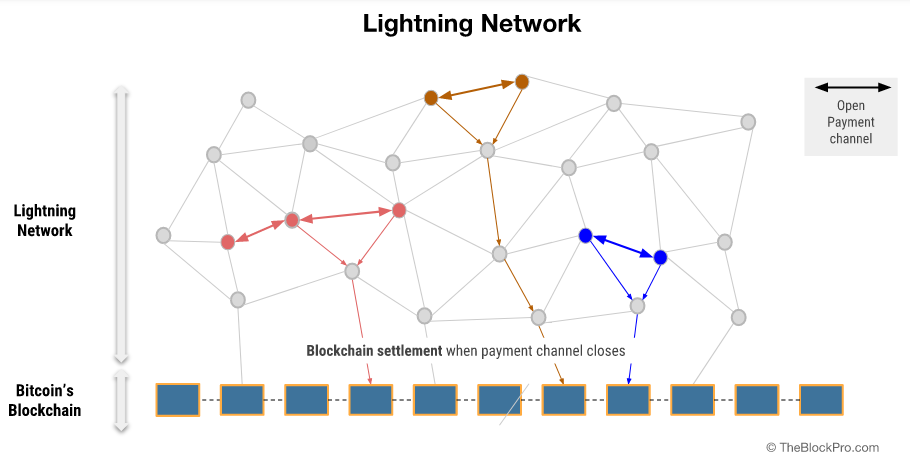
A state channel is simple. Let’s take a payment channel to understand the concept. Suppose you go to your neighborhood coffee shop every morning and pay in Bitcoin. It’s cool but cumbersome31 and expensive.32 What if you could open a “channel” with the coffee shop and sign a message that says you authorize the transfer of 1 BTC to them. But you only give it to them off-chain and don’t broadcast it to the network. The second time you come around, you sign a new message saying you will be transferring 2 BTC to them instead, and so on. At the end of the month, when you owe the shop 30BTC, the shop can send your latest signed message to the network and collect their 30 BTC. We’ve now replaced 30 payments over a period of time into 1 settlement TX on-chain.
An example of such an L2 is the Bitcoin Lightning Network.
Plasma
Other such Layer 2 solutions include Plasma, where a separate network33 can periodically commit the state on L1. The committed data is not enough to reconstruct the entire Plasma chain’s state - you’ll need to ask the Plasma chain for more data to do that. What happens if the Plasma chain nodes lie / withhold data is a data availability problem - a space with various solutions. The L1 only serves to keep the Plasma chain accountable to a certain degree.
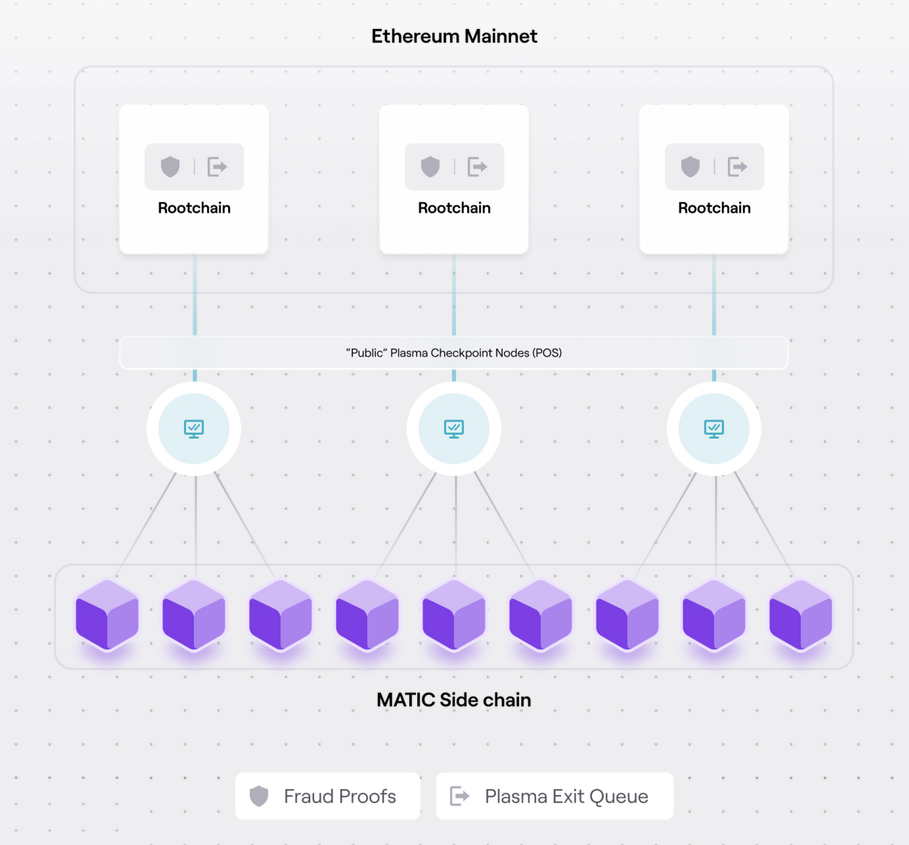
Rollups
Recently, rollups are getting a lot of attention. Rollups are essentially blockchains on top of blockchains. The entire Rollup state can be reconstructed from the data committed to the L1, which gives rollups robust security (the same level of security as the L1) and gives users the ability to force-exit their assets to the L1 if the Rollup Chain goes offline or turns malicious.
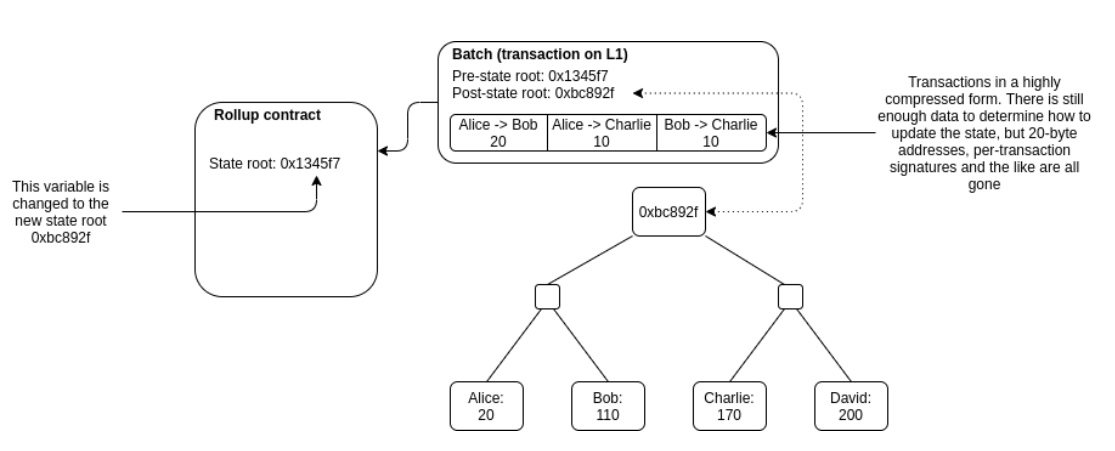
Sounds great but how do rollups work? In short,
- Rollups provide a Fair Sequencer (currently a centralized server) which orders the TXes
- Users send their TXs to Fair Sequencer. The Fair Sequencer runs the necessary computation to process these TXs, and changes the state tree accordingly. This moves the computation off-chain (i.e. computation run by L1 validators fot this TX batch significantly reduced)
- After some time (ideally once it has processed a significantly large batch of TXs) the Fair Sequencer commits some data to the L1 smart contract. This data lets anyone recreate the state of the L2 from scratch if they run an L2 full node. This moves data off-chain (i.e. data stored by L1 validators for this TX batch significantly reduced)
- This smart contract then secures the system with proofs.
- If it’s a Zero-Knowledge Rollup, the L1 Smart Contract verifies the zk-proof. A proper proof convinces the Smart Contract that the state-diff posted was the result of valid state transitions (without knowing what the transactions were - hence zero-knowledge!)
- If it’s an Optimistic Rollup, the L1 Smart Contract doesn’t do anything immediately. It marks this commitment as “pending” for a few days (challenge period), during which anyone can dispute the commit by submitting a fraud-proof (hence optimistic!)
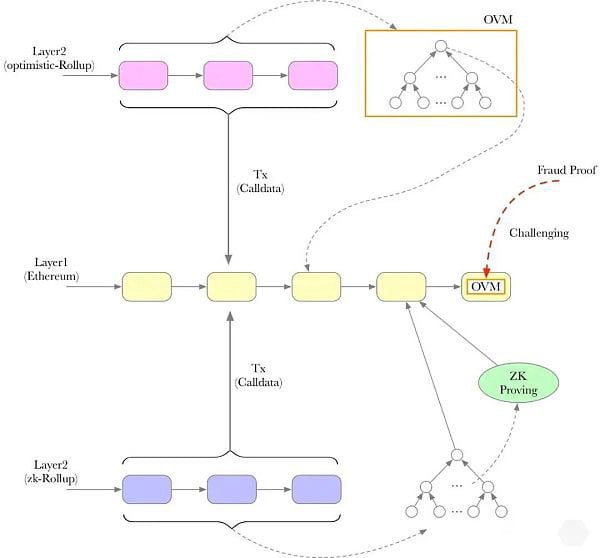
Rollups are an active area of research36, but they’ve been seeing accelerating adoption in the ecosystem thanks to their super low gas fees. Rollups also have additional vectors of attack. The centralized sequencer could censors someone, deprioritize some transactions, or go down due to bugs (or be taken down maliciously).37
To facilitate the rise of L2s, L1s like Ethereum are considering providing special transaction types called “Blobs” that are cheaper than regular transaction types.38 They can be cheaper because we know that the blob data doesn’t need to be executed by the L1 (since the L2 executes it). The L1 validators need not process/validate this data in any way. They just include it in the block as is, apply compression techniques, and (potentially) discard the data after some time, which all translates to less resource demand on the validator.
Sharp readers will be right to point out that this will most likely increase the amount of storage required by validators (since the validators have to store the calldata/blob posted at every blob). An interesting approach to keeping the storage requirements of a blockchain under control is to delete the history. Your bullshit detector should go off here! Wasn’t recreating the current state from genesis a fundamental tenet? History Expiry proponents argue that if you give the network enough time to download all the block data, full nodes should be able to delete older blocks in the interest of efficiency. Actors who need the data, such as indexers and archives, will be able to download whatever they need in the meantime. Note that this means full nodes won’t remember what the blockchain state was at a very old block height. They will still have to know the state tree at the latest block.
If you’re spinning up a new node, you should be able to fast-sync to the latest checkpoint from one of the archival nodes. If the incentive structures for archival and foolproof retrieval can be established, this becomes a low-hanging fruit. This is called “Weak Subjectivity”.39
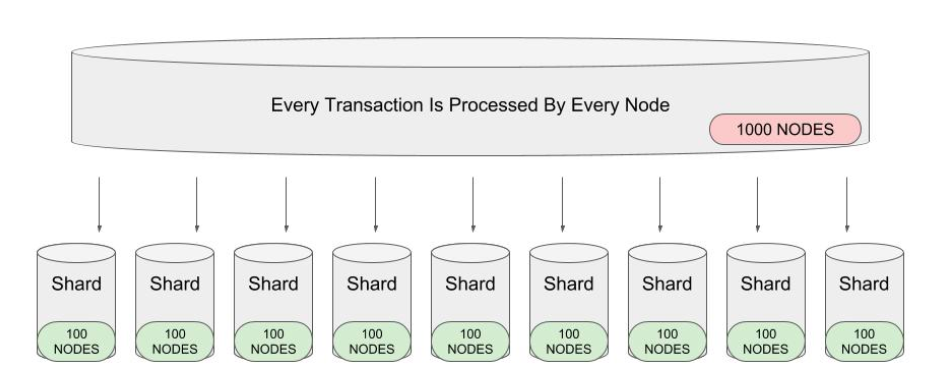
Divide and Conquer - Sharding
The idea in sharding is to split the validators into groups, and have them check only parts of the blockchain. Think of it as moving from a single-core computer to a multi-core computer that can process transactions in parallel.40 But this can get quite hard to coordinate - especially if a transaction includes interactions in multiple shards. Zilliqa and Elrond utilize sharding to scale, but we don’t know enough detail to comment further.
Execution Sharding was also part of the original Ethereum scaling roadmap.41 Since then, Ethereum has pivoted to a Rollup-centric roadmap. The bet is that Rollups will become the main consumer of blockspace on the L1. We need to be able to let the L2s do that without massive penalties, and increase how much data they can post on the block. So Ethereum is focusing on data sharding to keep the storage and network requirements of validators low so they can each verify only part of the block, and collectively verify the whole block (more on this in the PBS and DAS sections).42
Make it Cheaper to Check if Something is Wrong
There are 2 ideas in this space to maintain decentralization as we scale:
- Breaking down the work of the “Chosen Validator”43 into 2 parts - building and proposing - so we can decentralize block production further.
- Reducing the work of Validators44 so that light machines can successfully do the job - so we can decentralize block validation further.
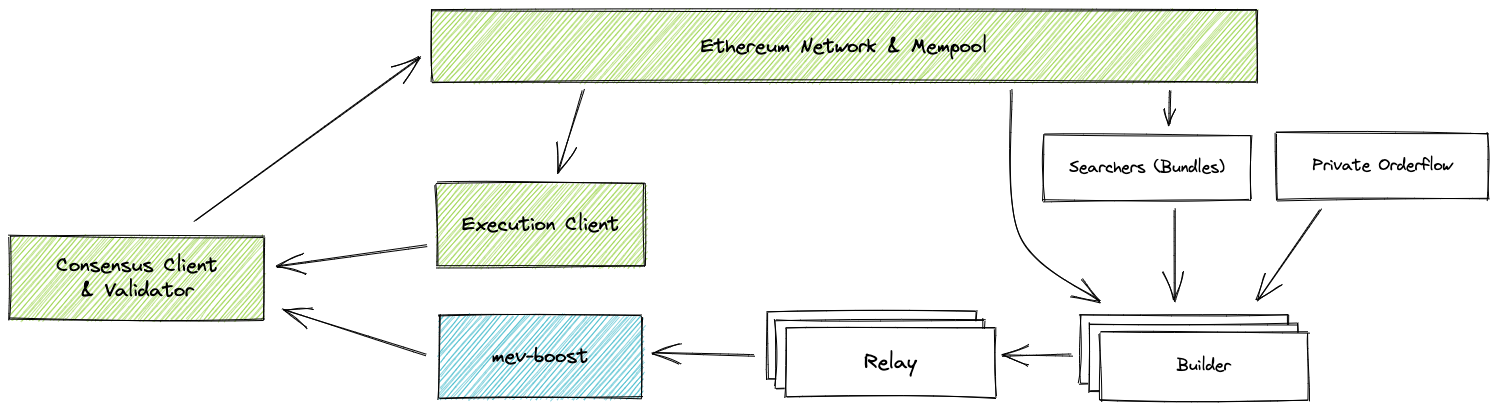
Proposer-Builder Separation (PBS)
Here the idea is that we will split the work of the validators into:
- Builders: A smaller set of people with large resources who will process all the transactions and group them into a block. They have some way to prove that they did the work. These builders can be beefy45 because we only need 1 honest builder in the network. (Honest Minority Assumption)
- Proposer: A different group then is responsible for checking the proofs (and the key here is that checking the proof is much less work than actually doing all the work). The proposer verifies a block statelessly46, which is why they can run on much lighter hardware.47 Put another way, Proposers can check the validity of a block using zero-knowledge proofs - without actually downloading the full contents of the block or reconstructing the state. As long as the proposer group is large and decentralized, the system will stay decentralized. (Honest Majority Assumption**)
This solution also helps in with another centralizing force - Maximal Extractable Value. MEV is the maximum value that can be extracted from the inclusion, exclusion, and reordering of TXs in a block.48
With a lot of MEV opportunities floating around (e.g. DEX price discrepancies), miners run complex algorithms to search for these opportunities. And the miners who can come up with the best MEV strategies can get better returns over time, than those who cant. This acts as a centralizing force where the smaller miners get out-competed since the large miners are willing to work for lesser block rewards. We might even see validators outsourcing this function to big farms that specialize in extracting MEV.
Protocols have to innovate MEV mitigation mechanisms to push back. This is especially important for Ethereum since issuance to validators after the merge will drop. Validators’ income sources will revolve around priority fees, incentivizing MEV.
With PBS, the builder isn’t the one proposing the block, so as long there is more than one builder, they would need to bid for the proposers to choose their block, and hence will share some of their MEV gains with the proposers to make sure they get included. We’ve effectively shared the rewards (Priority fees, MEV, etc) and incentivized everyone to cooperate.49
While PBS implementation is quite a ways off, Flashbots is helping to tackle the problem in the meantime with products like mev-boost, essentially creating an off-chain standard for democratizing MEV.
Data Availability Sampling (DAS)
PBS concedes the fact that block production will move to centralized entities and codifies defenses against malicious history rewrites and future interference. This is done by ensuring Light Proposers can keep the Beefy Builders accountable. Recall in “Vertical Scaling” we talked about how increasing blocksize will decrease decentralization. PBS aims to reach the holy grail - but we need DAS to get there.
Here, we further split the idea of validating a block into 2 parts:
- Check the proof for proper state transitions inside the block by the Builder/Producer.
- Ensuring the block’s data is available in the network.
Recall that in PBS, we’ve significantly reduced the computing power required to validate state transitions (#1). However, since the Validators haven’t seen the underlying data, they don’t know if the Block Producer shared the data. Without the data available for future reconstruction (e.g. if the Producer goes offline or turns malicious) nobody will know the current state of the blockchain.50 This is a form of Data Unavailability attack.
DAS is a way to do #2, ie. check if a certain block of data (let’s say 10000 transactions totaling 10MB) was made available by asking for any random sample of the data (let’s say only 10KB). So anyone can check data availability without fast internet, unlimited bandwidth, and a huge storage drive51
The basic idea is as follows:
- After a new block is produced, a validator could randomly and anonymously ask for parts of the TX data in the block from the producer.
- They should store this part and respond to other participants asking for this part52
- All the validators in the network do the same.
- Validators can reconstruct the block (by talking to each other and gathering missing pieces) if need be53
The problem with this naive solution is that a Producer can destroy trust in the entire system if they hide just 1 byte of data. To solve that problem, the Producer does something called erasure coding before Step 1. Erasure coding is a technique to “stretch” the data with redundancy. As long as any 50% of the stretched data is available, 100% of the original data can be reconstructed. To hide even a tiny part of the original dataset, the producer has to hide > 50% of this stretched dataset. This means that if you ask for 10 random samples from the stretch-set54, and all 10 were available, you can be 99.9%55 sure that the original dataset is available in full.5657

Another nice property we gain from DAS is that the more decentralized the validator network, the bigger the blocksizes can be safely.58 If you want to increase your confidence, just sample more parts! Holy grail!?59

The Multi-Chain Thesis
Let’s create more blockchains! Each chain has its own network of validators with custom parameters, governance, and consensus mechanisms. Each chain can specialize in a particular use case and tune itself accordingly. For example, GameFi projects can run on cheap and fast chains while DeFi runs on Ethereum for better security guarantees. We already live in this world since we have lots of “Alt L1s” such as Avalanche, Solana, Cardano, Polkadot, etc.
The problems with this approach are fragmentation of liquidity and loss of composability. Interoperability between different chains is not a solved problem.60 The Cosmos ecosystem has been working on these cross-chain problems for quite some time. They’ve come up with a generalized messaging protocol called the “Inter Blockchain Communication” (IBC). They want anyone to be able to spin up and customize a chain easily using open source projects like Tendermint Core, CosmosSDK, and Ignite CLI. In the Cosmos model, the validator sets are independent and don’t keep a check on the others. Each validator set can be small because the work is now split between the blockchains.

However, bootstrapping the security of a new chain is a difficult problem. Avalanche and Polkadot are trying to find a middle ground, where they have multiple chains which share security. In Avalanche, the Custom Chains built on top of the P-Chain have the option of using their own validator set, or delegating the security to a consenting Subnet61. Every Subnet must validate the Main Chain, but they can decide which Custom Chains to validate. Polkadot’s Relay Chain provides the Parachains with Data Availability and Cross-Chain Messaging.
Conclusion
You should now have a good understanding of various techniques protocols are using to scale blockchains.
In the future, we’ll be looking at some concrete examples of L1s trying to scale their ecosystems. This series should include the likes of Ethereum, Cosmos, Celestia, Polkadot, Avalanche, Solana, and more. Watch the space!
Follow us on Twitter for updates.
Join our Discord to discuss and learn together.

-
Jordan’s explainer here. Look at his other videos too, they’re excellent! ↩
-
Though we are going to focus on Proof Of Stake blockchains, most of the discussion will also apply to proof of work chains as well, just that some of the finer details will vary ↩
-
commonly referred to as a “ledger” because the database is used as an accounting system ↩
-
the technical term for this is “append-only” ↩
-
and the more diverse the validator set ↩
-
so that activity on-chain can continue uninterrupted 24/7 ↩
-
If there are multiple valid blocks for this round, they have a rule that they can execute independently to pick one. ↩
-
definition of “most” depends on the blockchain ↩
-
normal users, honest validators, developers, protocols ↩
-
the opposite of scaling ↩
-
In PoW, the simple act of showing the solution to the puzzle is enough to prove that work was done to create the block. A simple rule to follow the longest chain is enough because it is the one on which most work was done, and it’s very very expensive to maintain alternate chains without majority support. However, In proof of stake, proposing a new block costs almost nothing. So, you need to add a lot of safeguards in terms of rules everyone agrees to follow to ensure that a malicious block proposer is adequately and always penalized for cheating. Which adds a lot of complexity to the system. This is a topic for another blog post on blockchain consensus. ↩
-
often referred to as TPS, or Transactions Per Second ↩
-
Ethereum is mostly DeFi and NFTs at this point, and the data presented above does not take into account all the activity happening on other blockchains (or L2s on Ethereum like Arbitrum) ↩
-
e.g. Decentralized Social Media, more of the Finance industry, Metaverse, and Gaming ↩
-
There are fundamentally 4 resources a full node needs:
- CPU → To read and modify state, run smart contracts and check the validity of transactions, etc.
- Memory → To cache heavily used parts of the data so the CPU doesn’t have to wait around for it to load from storage.
- Storage → To store the snapshot of the blockchain’s world state at each block.
- Network Connection → To talk to peers in the network and receive broadcasts of new transactions to put in mempool [where TX is kept by nodes until included in a block], queries from light clients, and sync to the tip of the chain.
-
e.g. expensive GPUs, ASICs, mining farms ↩
-
intuitively, faster to coordinate 10 nodes than 1000 nodes ↩
-
more control = more assumptions you can make about the behavior of the system safely ↩
-
In fact, the “blocksize wars” raged on for years in the Bitcoin ecosystem until SegWit and lightning went live and the small blockers won. ↩
-
You could easily tweak the block time by adjusting the difficulty in the PoW algorithm, or changing a config in a PoS network - but you’ll have to balance that between cost to miners, TX fees, and UX for users ↩
-
On a PoW system, miners are incentivized to work on the longest chain. When a miner successfully mines a block, it broadcasts it to the system and starts work on building on top of it. The way miners know about a new block [so that they can validate it, stop trying to make a block on its parent and instead build on top of it] is by “gossiping” with their peers in the network. Owing to organic network topology and inherent latency, it might take a miner some time to receive the latest block. In this “gap” the miner will waste energy. Even if the miner does find a correct solution to the puzzle, the network would have already moved on and will ignore this “orphan” block. It is in the interest of the network to give miners enough time between blocks to “sync up” and reduce the proportion of orphan blocks. ↩
-
Having 2x more data per second would also mean the storage requirements for running a node would grow 2x faster ↩
-
such as an old phone or an Rpi you have lying around ↩
-
which makes it a permissioned blockchain ↩
-
The Solana Sealevel VM is also is also heavily optimized to make us of GPUs and multi-core processing to execute blocks quickly. Network propagation of packets is also similarly optimized. These techniques could arguably used in other blockchains as well, but they will come at the expense of inclusivity ↩
-
also known as moving computation “off-chain” ↩
-
you need to wait 60 mins at the cafe for 6 block confirmations ↩
-
the TX fee is more expensive than your coffee! ↩
-
with its own validator set and consensus rules ↩
-
the state’s hash is the root of a merkle tree for most blockchains as of now. The “state tree” mentioned in this article are merkle trees. Merkle trees are awesome since they allow compact proofs of large data structures (such as the Ethereum world’s state Storage). You can read about them here. ↩
-
ZK proofs are fascinating, but they require a lot of math to get your head around. If you’re not a math-magician, you can get the intuition behind how zk proofs are possible by watching this video from Numberphile. ↩
-
especially in the realm of generalizable EVM implementations with fast and/or succint ZK proofs ↩
-
Usually there is a way for users to bypass the sequencer and force a TX / group of txes via the L1 directly. ↩
-
The predecessor to this is EIP-4488, which suggested we reduce calldata gas cost ↩
-
Most PoS chains are comfortable with checkpointing. Even Ethereum’s CASPER will codify checkpoints lagging only 2 epochs (~64 blocks). ↩
-
each shard being 1 processor ↩
-
formerly known as Eth2.0 ↩
-
Data sharding is used in the world of centralized databases. In a sharded database with many nodes, the data (and operations over the data) is divided over the nodes. This means that no one node has the entire dataset, but it can be reconstructed by talking to multiple nodes [or having a node coordinate it, which is more common.] if anyone needs it [also for failure recovery, redundancy and some optimizations.] Even though most indie hackers can’t afford a SSD with 10TB of space, they can buy 15 with 1TB each and set up a 10TB capacity database. ↩
-
i.e. the validator randomly selected to propose a block in this slot ↩
-
Both the “chosen validator” and “attesting validators” ↩
-
Since they have to maintain the upto-date state of the EOAs and contracts, execute every transaction to change the states and search for MEV on top. ↩
-
”Stateless” means that you don’t need to reconstruct the state of the entire Blockchain to verify it ↩
-
e.g. doesn’t need a big, fast NVMe SSD ↩
-
To see MEV in action, you can create a smart contract, fund it with ETH and then have a public call that gives you back the ether. Someone will inject a tx before yours with a higher gas fee so it gets picked ahead of your tx. By the time your tx tries to get the ETH, the contract will already be empty. This someone can be a miner, in which case, they don’t even need to pay high gas fees. What’s protecting you from being censored is that the miner can’t be certain that they will be the first ones to create a block. But if all the miners can get more money from front-running you, then your tx will be delayed and it becomes a form of soft-censorship. ↩
-
The workflow with PBS may look like as follows:
- Proposers can receive TXs from users, put them in the mempool and give Builders the list of transactions to build blocks out of.
- Builders run their own algorithms to extract as much MEV as possible out of this list. They create a block and send it to proposers.
- Builders then compete on fees to woo Proposers.
- Proposers can commit to which bundle they’ll accept and then the Builder.
- Builder can reveal the data in the bundle. This way Proposers can’t “steal” the MEV.
- Even if Builder doesn’t reveal, Proposers will get the fee so Builder gets penalized!
-
even though we know the state transitions were done properly by the Producer! ↩
-
i.e. you can do it on a smartphone! ↩
-
for a limited amount of time if History Expiry is implemented too ↩
-
Note: we’ve achieved data sharding along the way too! ↩
-
regardless of the size of the original dataset ↩
-
1- 0.5^10 ↩
-
assuming other validators are doing so too, and that the Producer doesn’t know who the requests are coming from and hence can’t do selecting revelation ↩
-
The actual erasure coding scheme used in practice is a 2D coding with KZG commitments/fraud proofs. This is to ensure the erasure coding was done in a proper way (and not filled with junk by the Producer). This also ensures that the data can be recreated without the need for a super computer. Read this for more info: https://members.delphidigital.io/reports/the-hitchhikers-guide-to-ethereum ↩
-
given Builders can keep up with the clock ↩
-
It’ll be interesting to see what happens to light clients as the differences in resource requirements between light clients and validators decrease dramatically (You can still run a validators without staking if you don’t want the rewards) ↩
-
Suppose you want to use your BTC on Ethereum. To do so, you’ll have to “bridge” your BTC over. Most of these bridges today make trust assumptions that make decentralization maximalists queasy. In a nutshell:
- People send their BTC to an address controlled by Third Party, along with a memo of which Ethereum address should get the BTC.
- When Third Party’s “node” sees this TX on-chain, it mints a “wrapped” version of BTC on Ethereum.
- Reverse the process to get your BTC back on Ethereum.
The Third Party is the single point of failure. We’ve seen quite a few hacks of these kinds of bridges since these become honeypots for attackers. Once the funds are stolen, you can no longer redeem the Wrapped asset 1:1 for the native one. ↩
-
subset of validators with one or more common property ↩



Leave a comment